고정 헤더 영역
상세 컨텐츠
본문
머신 러닝을 통해 민감한 데이터 분류의 정확성을 가속화하고 향상시키는 방법
데이터 증가 속도와 하이브리드 IT 환경의 복잡성을 고려할 때 중요한 데이터를 검색하고 분류하는 것은 간단한 작업이 아닙니다. 최근 연구에서 IDC는 2022년부터 2026년까지 글로벌 데이터스피어의 크기가 두 배 이상 증가할 것이며 해당 데이터의 80%가 비정형 데이터가 될 것이라고 예측했습니다. 데이터 분류에 대한 기존 접근 방식은 노동 집약적이고 오류가 발생하기 쉬우며 쉽게 확장할 수 없는 수동 태깅을 사용합니다. 조직이 더욱 다양하고 사용자 중심적인 데이터 제품과 서비스를 만들면서 분류를 자동화하고 결과의 정확성을 향상시키기 위한 머신러닝(ML)의 필요성이 커지고 있습니다. 이 블로그에서는 Thales가 데이터를 분석하고 통찰력을 통해 학습하며 결과를 개선하는 데 도움이 되는 ML 모델을 통해 CipherTrust 데이터 검색 및 분류(DDC)를 어떻게 향상시키고 있는지 설명합니다.
가시성을 위해 다양한 데이터 저장소 탐색
데이터 검색은 전 세계 데이터 보호 규정을 준수하려는 조직의 첫 번째 단계입니다. 이 프로세스에는 온프레미스, 타사 서버 또는 클라우드 등 데이터가 저장되는 위치와 방법을 식별하는 작업이 포함됩니다. 조직은 기본 고객 데이터베이스 저장소와 같은 구조화된 데이터의 위치를 이미 알고 있을 수 있지만, 구조화되지 않은 데이터(예: 방향을 잃은 파일 및 이메일에서 발견된 데이터)는 찾기가 더 어렵습니다. 조직의 데이터가 발견되면 다양한 지표(예: 데이터의 민감도 또는 데이터에서 개인 식별의 용이성에 따라)에 따라 분류되고 상대적 위험에 따라 분류될 수 있습니다.
CipherTrust Data Discovery and Classification(DDC)과 같은 데이터 검색 및 분류 솔루션은 서버, 데스크톱, 이메일 및 데이터베이스, 사내 또는 클라우드에 저장된 데이터 세트 전반에 걸쳐 PII(Personal Identify Information)와 중요한 정보를 찾아 해결하는 데 사용되는 소프트웨어 도구입니다.
차세대 데이터 발견 및 분류
Thales는 상이한 데이터 포인트를 의미 있는 관계로 연결하기 위해 머신 러닝(ML) 모델과 패턴 매칭을 조합하여 사용하기 위해 DDC(CipherTrust Data Discovery and Classification)를 확장하고 있습니다. 이는 조직의 IT 시스템 내 어디에서나 데이터를 찾고 결과의 효율성과 정확성을 향상시키기 위해 분류를 위한 상황별 계층화를 의미합니다. ML은 문서 카테고리를 결정하기 위한 분류 또는 다양한 위치에서 중요한 데이터를 식별하기 위한 NER(Named Entity Recognition)와 같은 다양한 목적을 위해 다양한 유형의 모델을 기반으로 구축됩니다.
1) 패턴 일치: 데이터의 기본 분류 방법인 이 기술은 알려진 패턴을 데이터에 있는 정보와 일치시킵니다. CipherTrust DDC는 Ground Labs의 독점 패턴 일치 엔진인 Ground Labs Accurate Search Syntax(GLASS™)로 구동되어 모든 파일을 전체적으로 스캔합니다. CipherTrust DDC는 대부분의 지역 및 글로벌 데이터 개인 정보 보호 법률 및 규정을 다루는 250개 이상의 정보 유형(엔티티)으로 사전 구축되었습니다. 여기에는 이메일 주소, 생년월일, 전화번호, 주민등록번호 등의 개인 데이터가 포함됩니다. 은행 계좌 번호, 신용 카드 번호 등의 금융 데이터 그리고 환자의 건강 데이터. CipherTrust DDC는 또한 AES 키, 인증 비밀, SSH 키와 같은 비밀을 검색하여 하드코딩된 개인 키와 같은 보안 문제를 파악하는 데 도움을 줄 수 있습니다(여기에서 DDC가 지원하는 정보 유형의 전체 목록 참조). 또한 CipherTrust DDC에는 GDPR, PCI-DSS, CCPA, LGPD 및 HIPAA를 포함한 17가지 주요 데이터 법률 및 규정에 맞춰 사전 구축된 핵심 분류 프로필이 포함되어 있습니다. 패턴 일치 외에도 GLASS로 구동되는 CipherTrust DDC는 체크섬, 함수 호출 및 기타 데이터 검증 방법을 사용하여 거짓 긍정을 신속하게 삭제할 수 있습니다.
2) 정보 유형(엔티티)에 대한 NER(Named Entity Recognition): NER는 시간이 많이 소요되는 사람의 분석을 요구하지 않고 구조화되지 않은 텍스트에서 이름, 위치, 날짜와 같은 '명명된 엔터티'를 추출하는 자연어 처리(NLP) 방법입니다. . 예를 들어, 생년월일은 다양한 형식으로 제공될 수 있고 다양한 언어로 다양한 설명자를 가질 수 있는 명명된 엔터티입니다. 분류에 대한 기존 접근 방식은 "DOB" 및 "fecha de nacimiento"와 같은 키워드를 사용하여 컨텍스트를 계층화할 수 있지만 이는 다양한 유형의 문서나 글로벌 언어로 쉽게 확장할 수 없습니다. 대신 CipherTrust DDC는 NER를 사용하여 규모에 맞게 컨텍스트에 계층화할 엔터티 간의 관계를 찾습니다. 그림 1은 발견된 정보 유형과 각 정보 유형의 발생 횟수를 나열하는 스캔 결과의 예를 보여줍니다.ㅍ

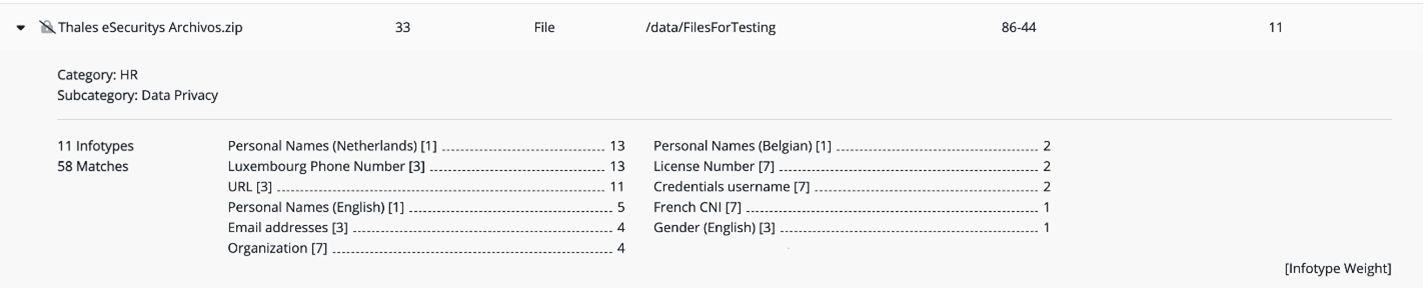
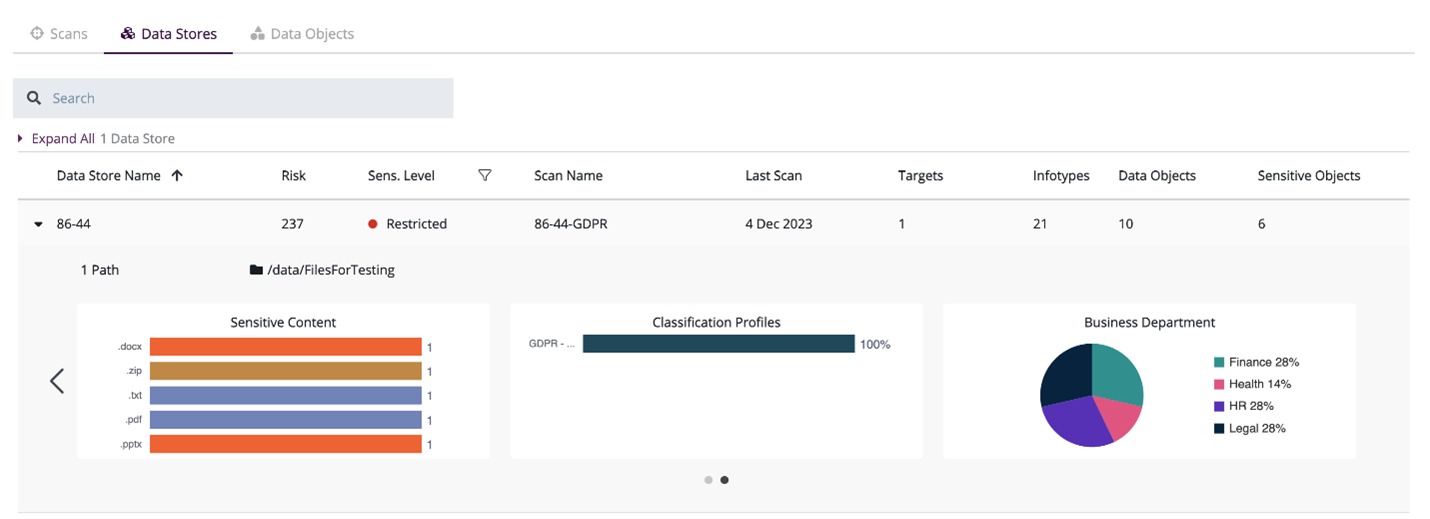
3) 카테고리 분류를 위한 머신러닝(ML): 다른 ML 모델을 사용하여 오브젝트의 내용에 따라 문서 카테고리를 결정합니다. 예를 들어 영수증이나 청구서는 PII가 포함되어 있을 가능성이 높은 재무 문서로 분류됩니다. CipherTrust DDC는 카테고리 분류를 위해 ML 모델을 사용하여 문서가 의료, 재무, 법률 또는 HR 관련 문서인지 높은 확률로 식별합니다. 그림 2는 선택한 데이터 저장소의 모든 문서에 대한 비즈니스 부서별 카테고리 분포를 보여줍니다.
다음 단계
올바른 툴을 활용하면 조직에서 데이터를 분류하고 컴플라이언스 규정을 준수하는 능력을 가속화할 수 있습니다. 현재 CipherTrust Data Discovery 및 Classification Machine Learning 기능을 개발 중입니다. 베타 프로그램에 참여하는 데 관심이 있다면 Thales에 연락하여 등록 목록에 참여하십시오.
Thales CipherTrust Data Discovery 및 Classification이 어떻게 데이터 관리에 민첩성과 자신감을 제공할 수 있는지 자세히 알아보십시오.
Thales CipherTrust Data Discovery 및 Classification이 어떻게 데이터 관리 알아보기
Thales DIS CPL소개
오늘날의 기업은 클라우드, 데이터, 소프트웨어를 활용하여 비즈니스의 중대한 결정을 내립니다. 전 세계 유수의 브랜드와 기업들이 클라우드와 데이터 센터에서 디바이스, 네트워크에 이르는 모든 곳에서 생성, 공유 및 저장되는 민감정보와 소프트웨어에 안전하게 접근하기 위해 탈레스의 솔루션을 활용합니다. 탈레스의 솔루션을 도입한 기업은 안정적으로 클라우드로 이전하면서도 확실하게 데이터 보안 규제를 준수할 수 있습니다. 현재, 매일 수백만 명의 소비자가 사용하는 서비스와 디바이스를 통해 탈레스의 고객들은 보다 큰비즈니스 가치를 창출하고 있습니다.
https://cpl.thalesgroup.com/ko
탈레스 소개
귀하의 데이터를 보호하는 기업들은 탈레스를 통해 자신들의 데이터를 보호합니다. 데이터 보안에 대해 중요한 결정을 내려야 하는 순간이 증가하고 있습니다. 암호화 전략을 수립하거나, 클라우드로 데이터를 이전하거나, 규제 준수 요구사항을 충족시켜야 하는 모든 순간에 탈레스를 믿고 찾아주십시오. 탈레스는 귀하의 안전한 디지털 트랜스포메이션을 지원합니다
'데이터보호 > 트렌드' 카테고리의 다른 글
| ENISA 2023 위협 환경 보고서: 주요 조사 결과 및 권장 사항 (0) | 2024.05.11 |
|---|---|
| 향상된 키 관리로 미국 정부의 과제인 클라우드 보안 격차를 줄이는 방법(#1/2) (1) | 2024.05.11 |
| MFA 및 패스키를 사용하여 피싱으로부터 조직을 보호하세요 (1) | 2024.05.10 |
| 성공적인 중앙은행 디지털 통화(CBDC)에 파트너십 참여가 필요한 이유 (0) | 2024.05.10 |
| AI 지원 통화 스푸핑의 영향과 이에 대응하여 할 수 있는 일 (0) | 2024.05.10 |




